最近在小象学院买了个课《Python人工智能》,课程涉及了一些基本的机器学习算法,也包含了几个机器学习的实战项目,虽然都比较基础,但是从中还是可以学到很多东西,今天天阴,正好就一起好好整理一下吧。
嗯……先整体归纳一下,在这门课程当中学到的东西,以及自己的一些感悟,再就每个不同的项目进行简单的分析。
先瞎叨叨几句
开始的开始,我们都是孩子……噗噗噗,stop,说正事!
1.机器学习的整个过程大致可以分为:数据收集、数据处理、构建模型、训练模型、预测结果。共五个部分。在这次课程的大作业中每一个项目都包含了除数据收集的其余四个过程。在真正完成一个项目时,由于对预测结果的追求,肯定不是说五个过程顺序走一趟就可以了,而总是一个循环往复的过程,不断尝试、不断改进,直到最终模型的预测结果达到让人满意的程度。
2.数据处理需要把收集到的人能读懂的数据,通过一定的方法和规则,转换成能够运算的数字信息。一般来说都是对其进行分类编码。在这一部分还可能要做的就是特征的取舍,因为并不是所有的特征都与结果相关。此外,收集到的数据很有可能包含缺失值,对于缺失值,可以选择放弃或是填充,在包含缺失值样本极少时可以放弃不完整样本;又或者,有某一个特征包含大量的缺失值,也可以抛弃这个特征;而填充策略则有:向上填充、向下填充、均值填充、中位数填充等。在这一部分啊啊啊,还可以通过图像来快速判断特征之间,特征与标签之间的关系,为之后的模型建立作准备。总之呢,就是把手头的数据处理的能够直接上算法使用,而且还要对特征与预测结果的关系心中有数(大概吧)。
3.构建模型不是随便拿一个算法模型套上去就好了,而是要根据对数据的把握和对不同模型的理解,尽可能的选择适合的一个或者几个模型。在实际情况中,构建模型和训练模型往往是分不开的,因为大部分模型的都包含有超参数,为了选择最好的超参数,和最好的模型,当然就需要在数据集上进行多次训练最后取其中最好的结果啦。
4.如果已经得到了满意的模型,那么只要将数据处理的过程和训练好的模型保存起来就可以对新的数据进行预测。
就每个作业仔细叨叨
一共五个大作业,分别为:IBM员工流失预测、贷款审批结果预测、员工流失预测进阶、蘑菇聚类分析、泰坦尼克幸存者预测。
IBM员工流失预测
该项目属于监督学习中的分类问题,主要目的是预测在未来一段时间公司的员工是否可能会离职。收集到的数据包括每一名员工的年龄、出差频率、职位等等信息,还包括作为标签列的是否离职信息。样本特征中既有数值型特征,也有字符型的标签特征。原作业点这里
因为这是第一个大作业,咱就梳理的仔细些,先来看看整个过程中都做了些什么吧:
- 引入可能用到的库、类或者函数,然后导入数据。
- 人工观察数据(这时候就需要一双慧眼和经验啦),搞明白每一列数据都是干嘛的,数据跟标签大概是个什么关系(一般领域靠常识还是能基本get到的)。顺便一行代码看看有没有空值,如果有就需要采取行动了,这个项目没有空值直接跳过。
- 这里使用了
seaborn.pairplot()对可能与标签值相关的一些特征(n个)与特征之间的关系进行绘图(n×n),方便快速查看特征对标签的影响。 - 单独用一个变量y来存放标签值;把数据集中的数值列和非数值列区分开来,将两种不同数据类型的特征名称存储在两个列表中(方便直接提取数据啊啦啦),便于之后的数据处理。
- 特征处理,用
pandas.get_dummiees()对非数值特征进行了独热编码(这个函数是真的好用)。 - 用
sklearn.model_selection.train_test_split()拆分数据集,1/5用作测试,然后应用scikit-learn中的模型对数据进行训练,因为是二分类问题,可以选择的模型比较多,这里选了五种:高斯朴素贝叶斯、决策树、KNN、支持向量机、逻辑回归。 - 在训练过程中,用for循环对每个模型的超参数都尝试了几个不同的值,并分别用列表记录了对应的准确率。
- 通过条形图直观比较不同模型的最优准确率。最后还用F1值(这个会更准确)对几个模型进行了评估。
(大概过程都差不多了,之后就主要针对数据处理过程和模型的选择进行阐述啦)
贷款审批结果预测
依然是一个二分类问题,需要模型的输出为是否同意申请人的贷款。原作业点这里
数据处理:
- 用
pandas.DataFrame.describe()简单统计了特征信息(这里得到的只有数值列信息),发现有缺失值。 - 重复值处理,根据ID判断,搜集到的数据中是否有重复样本。
- 缺失值处理,统计每一个特征分别有多少个缺失值,然后直接把有空值的样本删除了(好任性啊……)。
- 特殊值处理,把Dependents列的3+全部转换为3 。
- 根据特征数据的类型将所有特征分为了3类:数值型,有序型(比如受教育程度),类别型。将标签数据转换为数值型。
- 特征处理,对有序型特征进行标签编码,类别型特征进行独热编码(作业当中是先标签编码再独热编码,但是没必要这样啦),数值型数据进行了归一化处理。
- 把所有处理好的特征再合并起来。
模型选择:
- 使用网格搜索(GridSearchCV)来调整模型的重要参数,这里写了一个函数:输入训练数据、测试数据、模型、参数,输出训练好的最优模型、最优模型在测试集上的得分、训练时间。之后直接调用就好啦。
- 定义模型参数字典,关键字为模型名称,值为元组:(模型,参数字典)。通过for循环调用写好的函数对四种模型(KNN、决策树、逻辑回归、SVM)进行训练,返回值存储为DataFrame格式(方便之后作图比较)。
- 比较了不同模型的准确率和训练耗费的时间。
(这里的过程也是非常详细啦,所以再之后我们就只罗列一些值得注意学习的点了)
员工流失预测进阶
(数据和项目简介之前已经有了,不再赘述)原作业点这里
这里分别对数值型数据进行了归一化/标准化,比较了两种不同操作的训练结果;利用sklearn.model_selection.validation_curve绘制了学习曲线。
叮!当样本分布不咋均衡的时候,可以对样本进行重采样(pandas.DataFrame.sample()) 。重采样有两种策略,一种是向下采样(在我们的数据中,分类0的数据比分类1多,向下采样即将分类0的数据量缩减到跟分类1相等attrition_class_0.sample(count_class_1));另一种则是向上采样(向上采样即将分类1的数据量随机增加到跟分类0相等attrition_class_1.sample(count_class_0, replace=True))。
【选修】Python 的 imbalanced-learn 模块提供了更为丰富和科学的重采样方法。尝试使用imblearn.combine.SMOTETomek 来做上下采样相结合的数据处理。
蘑菇聚类分析
数据集包含了蘑菇的各种特征共22个,比如帽形、帽面、气味等等,所有的特征数据都是字符型的。原作业点这里
通过条形统计图直观展示了每个特征都有几类,以及每一类的数量,可以筛掉那些所有样本都相同的特征。ps.因为这种没有特色的,用了也是白搭啊哈哈。
虽然都是类别型数据,但也采取了区别对待。对仅包含2个可能值的变量使用一个简单的标签编码,对包含3个或多个可能值的变量进行热编码。
叮!使用sklearn.decomposition.PCA对特征进行了降维处理,在尽可能保留数据信息的同时减少特征的数量。
泰坦尼克幸存者预测
终于终于到这个非*儿有名的沉船问题了,然后就一起来看看什么样的人群在这次沉船事件中更容易活下来吧。原作业点这里
画图分析了每一个特征内的存活率(比如性别这一特征中,男性的存活率)。然后嘞,从这个图也能反映一些问题,比如说:不是每个人的仓位号都是独一无二的,说明这个特征竟然还有跟最后的结果有点关系的。
观察同一个仓位(比如E44)中的乘客信息,看名字发现他们还是有点关系的,然后把每一个人名字的Title提取了出来(比如Mr、Miss),有些title出现的次数很少,就把他们统一归位了一类-Misc 。
终极大盘点
后来的后来,渴望变成天使……
基本流程
这里不想瞎叨叨,先用一个流程图来理一理吧!(都能画流程图了,感觉自己很nb的样子吼^*-*^)
吭哧吭哧写好了代码,结果发现太长了,嘤嘤嘤,还是换图片吧。
ps. 这里提到的处理方法都很基础,不过嘞,这本身也只是对大作业的一个总结,理一理大概的过程,机器学习那么多方法,全部罗列也写不完啊……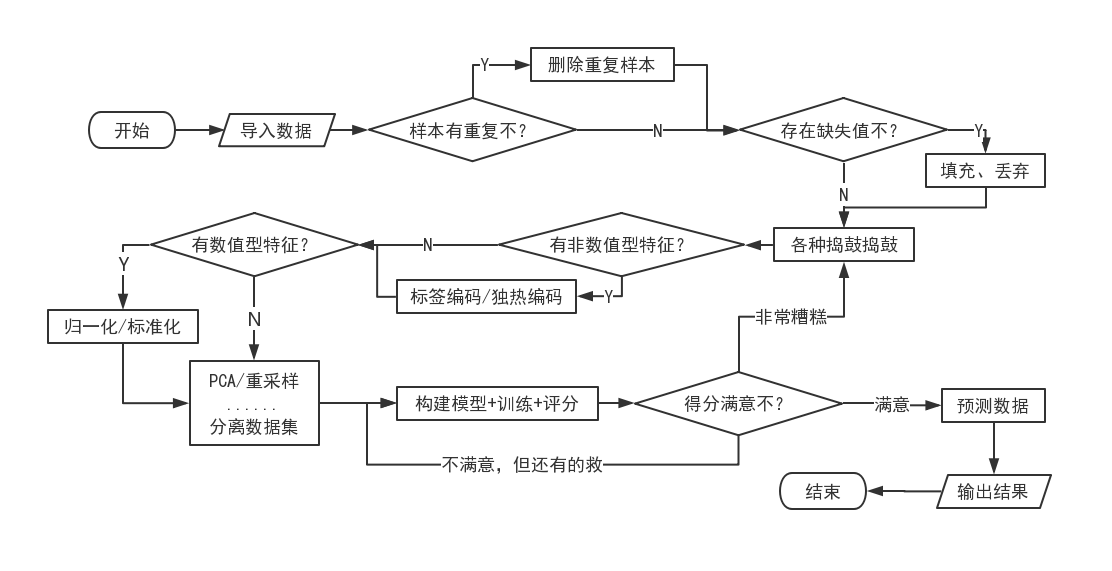
方法盘点
1 | import pandas as pd |
导入数据:1
2file_path = '(这里面是文件的路径以及名字。csv)'
data = pd.read_csv(file_path)
作图分析:1
2
3
4
5
6
7
8
9
10
11plt.figure()
#可视化属性之间关系
sns.pairplot(data[numerical], hue='Attrition_numerical',
palette='seismic', diag_kind = 'kde',
diag_kws=dict(shade=True))
#柱形图
data.plot.bar()
data.plot(x=column_name, y=['Survival Rate'], kind='bar',
title=column_name, legend=False)
#eheheha,其他的就不放在着了吧啦啦啦......
数据处理:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43#是否存在重复样本?(这里是根据ID判断)
data[data['ID'].duplicated()].shape[0] == 0
#是否有空值?
data.isnull().any() #会返回每一列是否有空值,bool型
#丢掉有空值的样本
data = data.dropna()
#空值填充
#Method.1
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values=’NaN’, strategy=’median’, copy=True)
data = imputer.fit_transform(data)
#Method.2
data.fillna(value=None) #直接指定填充值
data.fillna(method='backfill') #指定填充方案
#重采样
data.sample(sample_number)
#数据编码
#独热编码
#sklaern
from sklearn.preprocessing import OneHotEncoder
encoder = OnrHotEncoder(sparse=False)
data = encoder.fit_transform(data)
#pandas
data = pd.get_dummies(data) #这个函数可以保持原来的数据格式
#标签编码
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder(sparse=False) #每次只能对单一特征编码
data = encoder.fit_transform(data)
#数据降维
from sklearn.decomposition import PCA
pca = PCA(n_components=None) #指定一个数(整数或小数),可能小数会比较方便
data = pca.fit_transform(data)
n_components = pca.n_components_ #返回主成分数量
#数据拆分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data_X, data_y, test_size=0.2, random_state=1)
模型训练:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35#网格搜索
from sklearn.model_selection import GridSearchCV
clf = GridSearchCV(estimator = model,param_grid = param_range, cv = 6, scoring = 'roc_auc', refit = True,
verbose = 1, n_jobs = 4)
clf.fit(X_train, y_train) #训练后可以得到最优的模型
best_param = clf.best_param_ #返回训练得到的最优参数
best_estimator = clf.best_estimator_
train_score = clf.score(X_train, y_train)
test_score = clf.score(X_test, y_test)
#监督学习
from sklearn.neighbors import KNeighborsClassifier #KNN
from sklearn.tree import DescisionTreeClassifier #决策树-分类
from sklearn.tree import DescisionTreeRegress #决策树-回归
from sklearn.naive_bayes import GaussianNB, BernoulliNB, MultinomialNB #朴素贝叶斯
from sklearn.linear_model import LinearRegression #线性回归
from sklearn.linear_model import LogisticRegression #逻辑回归
from sklearn.svm import SVC #SVM-分类
from sklearn.svm import SVR #SVM-回归
#非监督学习
from sklearn.cluster import KMeans #K均值算法
#绘制学习曲线
from sklearn.model_selection import validation_curve
train_score, test_score = validation_curve(DecisionTreeClassifier(), X_train, y_train,
param_name='max_depth', param_range=param_range, cv=10, scoring='roc_auc')
train_score = np.mean(train_score,axis=1)
test_score = np.mean(test_score,axis=1)
plt.plot(param_range,train_score,'o-',color = 'r',label = 'training')
plt.plot(param_range,test_score,'o-',color = 'g',label = 'testing')
导出数据:1
2
3y_pre = model.predict(data_to_pre)
result = pd.DataFrame({'ID': list(range(len(ypre))), 'pre_value': y_pre})
result.to_csv('文件路径及名字')